The Future of AI is on the Edge

Software development is at the forefront of the LLM AI revolution. It is perhaps the first profession to be significantly impacted by the technology. The trends that we see in the software development profession are likely to be replicated across other professions too. This is, in effect an early tell on what wide changes are likely to happen as AI (and LLMs in particular) impact other industries and professions. The economics of that trend increasingly point in one direction, AI is moving to the edge.
AI has had a positive impact on productivity for software developers. However, the way it is delivered and how it is charged for is causing a growing number of developers to consider giving up on the big AI providers, like Anthropic and OpenAI and instead look at running less capable, but still “good enough” AI models much more cheaply on their own hardware.
How AI is Delivered to a Software Developer
It is perhaps not surprising that software development is one of the first industries to be impacted by AI, after all it is largely other software developers who are creating the technology.
How Developers are Charged
Anthropic and OpenAI take on the huge cost of training the initial model or neural network. Please check out the Super Quick Primer on AI Models on my blog for some background. Then they host the model in their cloud, and allow developers to connect to it over the internet. When presented with a coding problem, these models are likely to produce a useful and often correct response.

Introducing the AI Agent (Coding Agent)
For AI based coding to be effective, the AI model often needs access to significant parts of the codebase, build output, tests, documentation, and developer instructions. Feeding all this data to the model by hand is painful, so AI Agents, or Coding Agents have appeared. These are small applications which run on the developer’s computer and automate this communication with the model. They’ll take the model’s response and automatically generate the code on the developer’s machine, ready for the developer to review.
The Pay Per Use Charging Model / Pay per Token
Both Anthropic and OpenAI have effectively, produced pay-per-use charging models. These are all based on tokens. There are tokens used when the data is supplied to the model, and of course when the model produces an answer. Tokens can also be created and consumed when the model is “thinking”.
How a Simple Request can Consume a Lot of Tokens
AI coding agents can multiply token use because they may repeatedly call the model: reading files, planning, editing, running tests, interpreting errors, and trying again. Some reasoning models may also consume additional hidden reasoning tokens.
This really does make the output better, but it also makes initial requests consume more tokens per request. As developers are charged per token, this means that requests can get pretty expensive.
This pay-per-use charging model is new for developers. It directly ties all coding to an additional fee. Developers are not used to this charging model, at least, not for code production tools. While there are productivity gains, there is still an additional cost per line of code written. This is new.
Commercial Evolution of Software Development Tooling
Software development tooling has gone through several evolutions. Back in the ’80s during the home computer boom, development could be done on the computers themselves. They came bundled with a programming language and tools. They often lacked in usability, but to the developer this appeared, effectively, for free.
The arrival of DOS and Windows brought with it a surge in commercial tooling. Companies like Borland and Microsoft supplied these tools. To the developer this was usually a single one-off purchase.
As Linux and open source software became dominant the developer tools returned to being, effectively free for the developer. The costs of these tools have been borne by companies like RedHat (IBM), Intel, ARM, AMD and others.
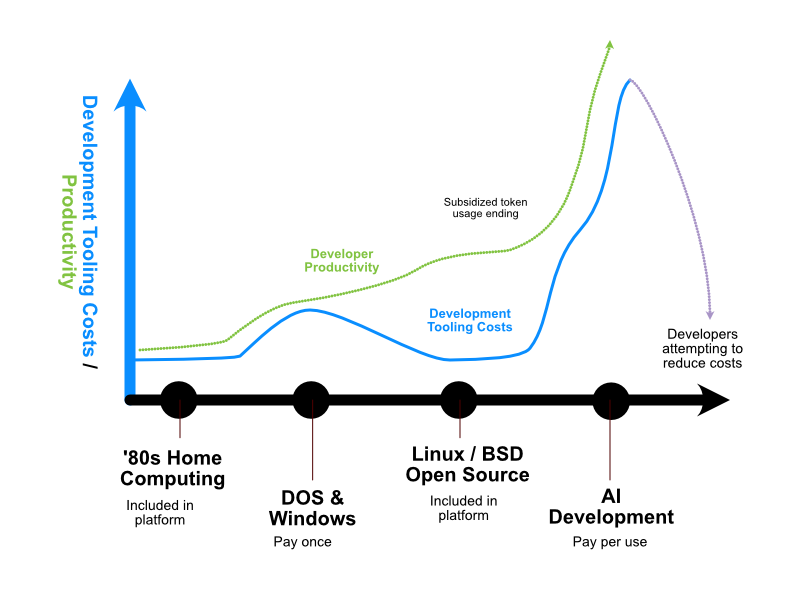
AI development returns the developer to having to pay for access to the tooling. But most importantly, it forces the developer to pay every time they use the AI tooling. Every token, every input and every request costs money.
You can’t be Slow
AI does provide real productivity gains, not using it puts every developer at a commercial disadvantage. The competitive nature of the technology industry is going to force developers to continue to use AI tooling. The logical conclusion of this is that developers will become dependent on the small number of suppliers of the AI models, and these suppliers, will effectively, charge them for every single line of code written.
The Rising Costs of AI Development
The cost of using these models is rising for perhaps two key reasons:
-
The model complexity is increasing, and models are doing more thinking. This consumes more tokens, increasing the cost per request.
-
The major AI companies are operating at a loss. Their income (generally from inference) does not cover their outgoings.
For both Anthropic and OpenAI there are three ways out of this:
- Charge more
- Serve a vastly larger number of customers
- Reduce their operating costs
The low cost of inference today helps to capture market share, which should help bring in more revenue to offset the huge costs associated with creating the model in the first place. Much like when Uber and Amazon were first launched, operating at a loss to capture the market. In both Amazon and Uber’s case once the market was captured, then prices started to increase.
The Impact of the Cost Increases
These rises in the cost of AI are being directly felt already within our industry. I’ve been speaking to several developers from multiple organisations, and the results are really interesting.
One contact recently told me that he had priced the cost of running an AI agent to generate a set of tests. He’d carefully taken note of the number of tokens that were used and had calculated the cost of the support. It came in at €75 / hour. A developer from a country with a lower cost of living, like India could be obtained for €65 / hour.
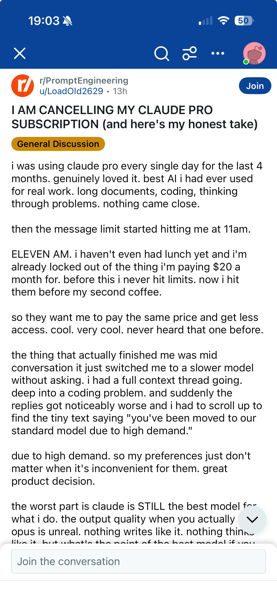
Another contact at a small company explained that on his current Claude Code plan, he can exhaust his weekly allocation of tokens by 10am on a Monday morning. Making as he put it, “Claude Code effectively useless”. He isn’t the only one reporting the same thing.
This is probably a smaller scale version of what recently happened with Uber, whose technology teams managed to consume their entire year’s budget for AI tooling in just 3 months.
Offsetting Costs and Still Gaining the Benefits of AI
The productivity gains are clear. The question is how does a software developer leverage these gains at a price point and costing model which makes sense?
The Supply of AI Models
Creating an AI model is incredibly expensive. The models are increasing in quality, and producing better results, however this comes with additional complexity and size. This in turn means that the compute power required to host them is also increasing. To give you an example the largest publicly disclosed model I can find is the Meta Llama 4 Behemoth, at nearly 2 trillion total parameters (weights)!
Local Models are Good Enough
Companies like ChatGPT and Anthropic offer their models via a cloud service. There are other providers who give away open source models. These open source models can be downloaded and run on a developers own machine. These are, obviously, vastly cheaper than the cloud versions. Traditionally it’s been accepted wisdom that the cloud models provided by ChatGPT, Anthropic etc, have been of a higher quality than the self hosted versions. But that opinion is starting to change.
Taking into account the vast difference in cost between the cloud and self hosted versions, developers have found that, bang for the buck, the local models might just be good enough.
Reducing the Cost of AI with Self Hosting
High-end Apple Mac Minis have been flying off the shelf. My recent attempt to purchase one this weekend was thwarted. I was reliably informed by the staff at my local Apple store that new Mac Minis will be available some time in August (it’s currently May). The main cause of this issue? - Folks are buying the Apple Mini’s to run a local LLM. In response Apple has raised the Mac Mini price. If you check on line you will find a number of blog posts and articles, like this one helping you fine tune your model on your hardware.
It is not just Apple which have products which are great at running local AI, AMD does too. AMD’s latest AI specific processor is available in several products today.
Locally hosted models have often been considered inferior to their cloud-hosted brethren. However, Simon Wilson, an experienced open source developer, entrepreneur, and LLM watcher, gave a recent presentation in which he reported that over the last 6 months “local models widely outperform expectations”. Bang for the buck, locally hosted models are becoming more attractive.
Running a self hosted model can be slow. The models do require a lot of computational support and large amounts of RAM. But even a slow running model can deliver productivity gains. After all, the AI models do not need to sleep.

One startup I spoke to mentioned that they were purchasing a Mac mini to run a Chinese AI model Qwen. They had found that Qwen was good enough for what they needed, they were able to leave the Mac mini running overnight and collect the resulting code changes in the morning. This is still a large productivity gain, but at a fraction of the cost of using a cloud based AI service.
Looking into the Future
Developers can grab a model to self host, for free from sites like Hugging Face. As folks transition away from paying for the cloud model, it is possible to imagine a future in which these self-hosted models will be charged for.
However, charging for a model faces one huge issue. Piracy. The models available to download from Hugging Face are, essentially, just large data files. They can be copied and shared. If you wanted to monetise the model this would be a problem.
What if you found a way to distribute the model in a format that is difficult to copy, and one which delivered huge performance benefits to your customer? Instead of running 18 or 8 tokens a second as is possible on a M4 Mac, you could get something closer to 14,000 tokens a second?
The AI Chip

Typically the machines running the models will use a GPU (Graphics Processing Unit) to perform the hard number-crunching the models require to operate. While this is way faster than using the PC’s normal processor, it is still expensive and power hungry.

Something new is emerging. In March this year (2026) CERN announced 1,2 that they were using specialised models compiled into hardware designs targeting FPGAs or ASICs. They had developed hls4ml a transpiler, that would allow a model to be converted to a format which can be burnt onto a chip. This wasn’t creating a design with tensor processors, this is placing the model and its weights directly into the silicon. This allowed their models to operate at an impressively fast speed. It also eliminated the huge memory and power requirements that GPUs and traditional AI computation uses.

Just two months before CERN’s announcement a Canadian company, Taalas 3 announced that it had taken Meta’s open model, “llama” and had burnt that onto a chip, similar to CERN’s approach. This had, according to the company resulted in a 1000x performance boost at a fraction of the power costs of GPUs.
The Advantage of the Chip
You could imagine, that in the future, putting the AI model onto a chip might be attractive for the AI companies. They could distribute and share a version of their model in a format which is very difficult to copy. For the customer, the developer, it provides them with a naturally accelerated AI implementation. The initial first wave of these AI model on a chip processors are blindingly fast. Taalas has a product demonstrator that appears to deliver llama 3.1 8B with over 14,000 tokens a second. Taalas claims that this is being delivered at 1000x less power than a GPU. This is a huge step change.
Taalas are not alone in the journey, other companies like Mythic AI are also following this trend. Mythic’s approach is to return to analog computing as a way to deliver the weights and mathematical transformations required by an AI model.
Burning the Model into Stone
Once you burn the AI model onto a chip the model essentially becomes “locked” you can’t change it. It is, effectively written in stone. Developers who take the AI chip will be locked into using it for several months if not years before changing it. At first this could seem to be concerning. What if a new model is released?
But as we’ve seen, this isn’t the question developers are asking. Developers are asking about productivity gains. Would the developer who purchases the chip and uses the incredible speed for productivity gains be significantly further behind a competitor in 24 months? - Because the question is not about having the latest model. The question is about the ability to deliver cost-effective productivity gains.
We have developers effectively making this call today. They are selecting the self-hosted models, which are not as advanced as the cloud versions, but which are “good enough”.
The Chip in the Future
In the future we can imagine the latest AI models arriving as expansion cards for PCs, even as USB sticks, or M.2 cards. Outside of the PC ecosystem these chips could appear in our smartphones. The next time you go to upgrade to a new iPhone, you will actually be getting a smarter phone - because it has a smarter chip.
The Impact for Developers
It is widely expected that the cost of AI inference that developers experience today will increase in the future. Even the current costs are starting to bite and developers are actively turning to self hosting models as an alternative. The arrival of a chip based AI solution should, actually make this easier for developers and could provide a viable way forward for the industry.
It is also perhaps indicative that the limits of the software engineering market are starting to be reached. For a growing number of developers the additional benefit of the latest models on the cloud doesn’t justify the costs being charged.
Feedback Welcome
I’m a firm believer in holding strong views lightly, it’s a fantastic way to peer into the future, and a great way to start a detailed conversation about a given topic.