A Super Quick Primer on AI Models

This is a very quick primer on AI models. It explains some of the details behind what they do and how they are constructed. I’ve been doing a dive into the economics of AI and the impact on software developers. This blog post stemmed from that research.
A little bit of a technical background helps to understand the economics of the AI supply chain. The AI Models we talk about today are neural networks. The phrase neural network sounds very science-fiction but it’s actually, as a concept, not that complicated. The neural network is a network of numbers and mathematical operation loosely inspired by the human brain.
A Mathematical Model Loosely Inspired by the Human Brain
The human brain is a collection of neurons, one neuron can connect to multiple other neurons via a set of synapses. Each neuron takes an electrical signal as input, and generates another electrical signal as output. There is a chemical property of the neuron which determines what output signal it generates when presented with new input signals.
A neural network is a mathematical system loosely inspired by the human brain. The classic building block is the perceptron: a unit that takes numerical inputs, applies weights, combines the result, and produces an output. Modern AI models are vastly more elaborate than a simple perceptron network, but the core idea remains useful: the model is a large graph of weighted mathematical operations.
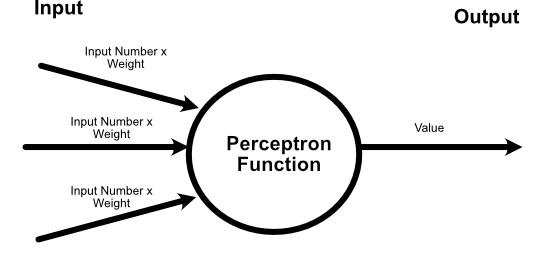
In an AI model there can be millions, if not billions of weights each on a connection between various mathematical operations. This forms a large graph. Hence the phrase neural network.
Training a Neural Network
At a high level, training a neural network is like learning “by rote”, the network is shown, say an image of a dog, and we know in advance that this is an image of a dog. We expect the network to report back that this is a dog. If the network doesn’t do this we update the weights in the network. There are several different algorithms which determine how to update the weights, but they all try to do the same thing - get the network to report the correct answer when shown the input data. In reality this means showing the network a lot of images of dogs, and also images which are not dogs. This is known as training data.
Training is expensive. It requires huge amounts of data and huge amounts of computing power. The computer must run calculations through the network, measure how wrong the answer was, and then work backwards through the model to adjust the weights. This process is repeated many times. This repeated adjustment of weights is where much of the cost of building large AI models comes from.
Inference : Using a Neural Network
Once trained, a model can be used. For example a model can be shown an image of a dog it has never seen before, and the model should be able to correctly identify the dog. This use of a trained model is called inference.
Compared to training, inference feels cheap. The computer still needs to run calculations through the network, but it does not need to update the weights, and it does not need to repeat the learning process millions of times. It is still a relatively complex operation because the networks are large, but it’s a tiny fraction of the work that the training process takes.
Commercial Neural Networks (aka Models or LLMs)
Companies like Anthropic, OpenAI, and others have been training their own neural networks. Instead of training them on images directly, they’ve been trained on language. Huge amounts of text. These neural networks are referred to as LLMs, or Large Language Models. These are trained by getting the model to predict the next word in a sequence.
Introducing the Token
But models are all mathematics, they understand numbers, not words. So the LLMs break down words in to “tokens”. These tokens represent sum, or all of a word. How they do this is model specific, OpenAIs model will work slightly differently to Anthropics, but at their heart they are all doing the same thing, taking words and making them numbers.
Of course as the model is based only in mathematics, when the model generates a response, it generates a sequence of numbers (tokens) and these tokens need to be converted back to words.
This is also why AI systems often talk about “context windows” and “token limits”. They are not counting pages or paragraphs. They are counting the chunks of text that the model can process.
Impact on Software Development
It just happens that training a model to predict the next token in a sequence is very handy for solving a whole bunch of problems. Including programming.
Programming languages, are just that, languages, and one of the tasks the LLMs are very good at is predicting how to complete code, and even how to generate code when told what to do. At one level, this is statistical pattern learning over very large collection of code and text. The result is not human understanding, but it is often useful enough to automate real development work.
As these models can make developers faster, automate parts of software creation, and reduce the cost of producing code, in doing so they do not just change technology, they change the business model around creation software itself.