4 Things to Consider When Adopting WebAssembly for Embedded Systems - Part 1 Compilation.
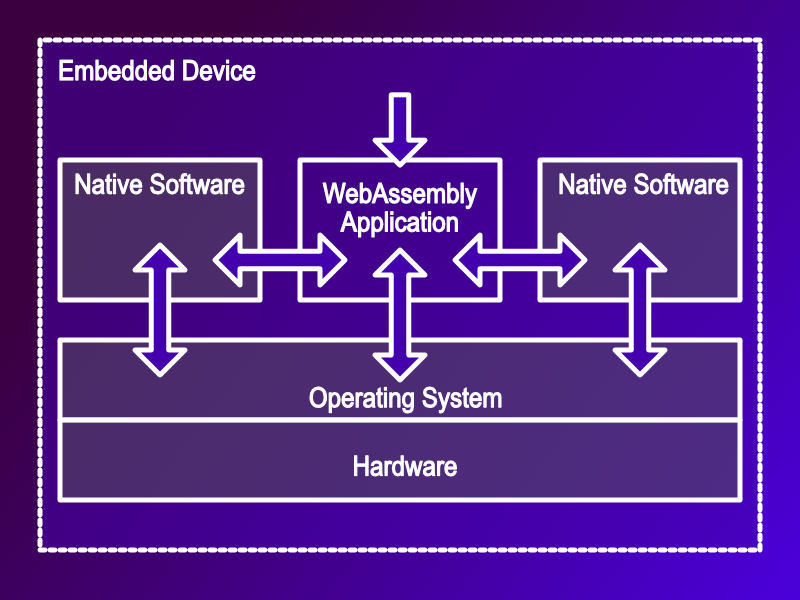
There are really great reasons to adopt WebAssembly for embedded systems. But there are probably 4 key challenges any team or developer encounters when using WebAssembly on embedded systems. These are:
- How to compile to WebAssembly
- Which runtime to use
- How to integrate your WebAssembly application on your Embedded System
- How to deploy your WebAssembly application
It is a lot to consider. I will do a series of blog posts focusing on each item in turn. In this post I am going to focus only on the first item, how to compile to WebAssembly. Here I will list out the challenges and tips on addressing them.
Compiling your existing code to WebAssembly
I mentioned in my last blog post “Why WebAssembly on Embedded Systems” that there are some awesome reasons for using WebAssembly on an embedded device. The major reasons include sandboxing - the ability to isolate code running on the device, and a common compilation target which will work across a range of devices. But just like any compilation target WebAssembly has its own quirks and I’m going to cover some of them here. For the most part, a lot of existing ‘c’ code will compile over to WebAssembly will minimal changes. However there are a few gotcha’s to watch out for.
TIP: Indexes and Array
I’ll give this tip early, and you will see it play out across various items which I’ll talk about later. Basically almost every data structure which is used to represent WebAssembly is an array. Functions, as you’ll see they are treated as indexes in an array or table. Data types, and index into a structure, linear memory (the WebAssembly version of RAM) - yeah, that’s an array too. It makes a lot of structures easier to understand, and it produces some interesting side effects.
Harvard v Von-Neuman
WebAssembly is a Harvard machine, not a Von-Neuman machine (like the one you are probably using to read this article). A Von-Neuman machine stores the application code and data in the same memory, where as the Harvard machine stores the application code in a separate memory from the data. In the Harvard machine the two memories can’t directly interact with each other. This means that it is impossible to do a direct function pointer on a Harvard machine. This has some interesting implementation constraints.
Tip: A function pointer in WebAssembly is really an index into a table
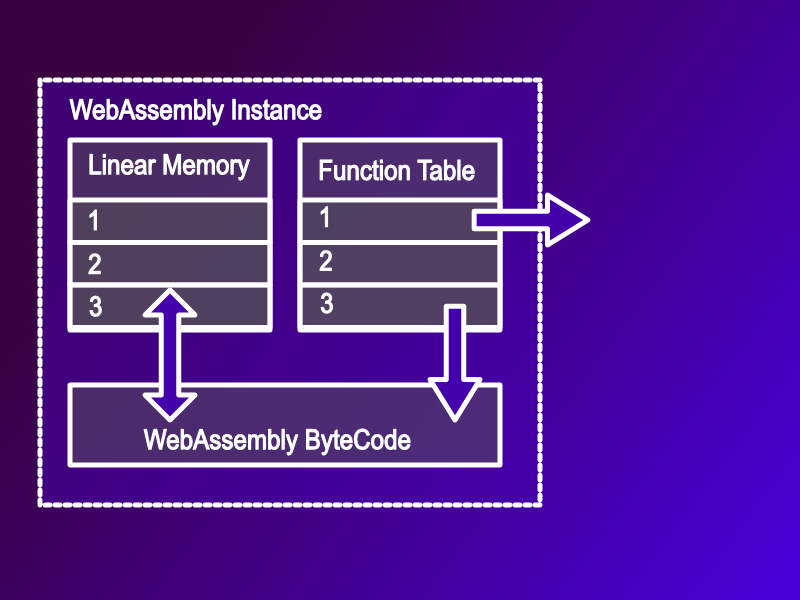
On a Von-Neuman machine the code is in the same memory as the data. As a function pointer is a data item, and it can just store the address of the function. On a Harvard machine the function isn’t directly addressable from data, so it’s not possible to store this address in the function pointer. To get around this restriction WebAssembly provides a function table. This function table acts like a translator. It keeps the actual address of the function hidden from the WebAssembly code and instead allows the WebAssembly code to refer to the function via an index into the table. You can see this if you try to print out the address of a function pointer:
// example.c
#include <stdio.h>
typedef void (*TFunctionPtr)(void);
void function_a(void) { printf("I am function : %s\n", __func__); }
void function_b(void) { printf("I am function : %s\n", __func__); }
int main(void) {
TFunctionPtr ptr = &function_a;
printf("The address of function_a is %p\n", ptr);
ptr = &function_b;
printf("The address of function_b is %p\n", ptr);
return 0;
}
If you run this natively you’ll get the address of the functions as they appear in a Von-Neuman machine:
$ clang -o example.native ./example.c
$ ./example.native
The address of function_a is 0x559674f29140
The address of function_b is 0x559674f29180
And if you run this via WebAssembly (this uses the WAMR runtime) you see the indexes into the table:
$ /opt/wasi-sdk/bin/clang -o example.wasm ./example.c
$ iwasm ./example.wasm
The address of function_a is 0x1
The address of function_b is 0x2
Behind the scenes there is a table doing something similar to this:
| Index | Function Details (hidden) |
|---|---|
| 1 | function_b’s address |
| 2 | funciton_a’s address |
If you would like to learn more check out my blog post introducing the extern_ref.
Memory Management
WebAssembly translates all memory accesses into read and write (load and store) operations which address an array of bytes. This means that pointers become index values for the address in the array they refer to. Each WebAssembly module, will by default, have its own byte array (also referred to as “linear memory”) which it does not share with other modules. This has some unusual effects, some naturally to be expected, and others perhaps not so much. There are probably 3 key side effects developers will encounter.
Tip: Consider WebAssembly a 32 Bit machine (For Now)
WebAssembly is also 32bit only, at least for now, so applications are generally limited to 4GB of RAM. This isn’t a problem for most applications in the embedded space. But as always when porting software it’s important to know the pointer sizes, and memory space available. This is particularly true if you are embedded WebAssembly onto a 64bit embedded system - the host system will be 64bits, but the WebAssembly code will be 32 bit. Of course, this also means that pointer sizes are 4 bytes instead of 8.
Tip: Actively check for Reading and Writing NULL
All memory accesses in WebAssembly are translated into offsets, and offset zero is a valid memory address! - So you in a C application you can dereference NULL and write to it! - Be careful. So NULL pointer dereferences do not trap.
// null.c
#include <stdio.h>
#include <stdint.h>
int main(void) {
uint32_t* iPtr = NULL;
printf("The value stored at %p is %d\n", iPtr, *iPtr);
return 0;
}
Running the code above natively, results in this:
$ clang -o null.native ./null.c
$ ./null.native
Segmentation fault (core dumped)
And running in WebAssembly gives this:
$ /opt/wasi-sdk/bin/clang -o null.wasm ./null.c
$ iwasm ./null.wasm
The value stored at 0 is 0
The same effects are observed using C++ and nullptr. Parameter validation and using asserts to validate parameters become pretty important.
Tip: Constant Data is only constant at compile time
Typically we’d use the const key word to ensure that the data structures we define are constant and are completely unmodifiable. This is typically enforced at compile time and at runtime. At compile time in C and C++ we’d see compiler errors if we try to modify a constant value, and at runtime the constant data is held in constant (read only) memory, so if we try to write it, the machine will catch this as we’ll see an error.
Consider the following code:
#include <stdio.h>
static const int KInt = 42;
int main(void) {
KInt = 12;
printf("KInt is %d\n", KInt);
return 0;
}
This will generate a compiler error for both native and WebAssembly:
./const.c:4:8: error: cannot assign to variable 'KInt' with const-qualified type 'const int'
4 | KInt = 12;
| ~~~~ ^
./const.c:2:18: note: variable 'KInt' declared const here
2 | static const int KInt = 42;
| ~~~~~~~~~~~~~~~~~^~~~~~~~~
1 error generated.
But we can cast away the const, and write to it. Like this:
// const.c
#include <stdio.h>
static const int KInt = 42;
int main(void) {
int* ptr = (int*)&KInt;
printf("KInt is %d\n", (*ptr));
(*ptr) = 12;
printf("KInt is %d or %d\n", (*ptr), KInt);
return 0;
}
If we run this on native we see a crash:
$ clang -o const.native ./const.c
$ ./const.native
KInt is 42
Segmentation fault (core dumped)
But if we compile this for WebAssembly and try again it will work!
$ /opt/wasi-sdk/bin/clang -o const.wasm ./const.c
$ iwasm ./const.wasm
KInt is 42
KInt is 12 or 42
As you can see the results are inconsistent. You’ve have expected if it had worked for the value to be 12 for both the dereferenced pointer (*ptr) and the constant KInt. What’s actually happening is that the compiler is optimising here, and replacing the KInt with the value 42, since at compile time this is a constant and therefore cannot change.
So, writing to constant data, while technically possible really should be avoided. It will be impossible in the near future, as there are moves in the standardisation body (W3C) to add full memory controls including constant / read only data.
Linking and the Logical Structure of WebAssembly Modules
When code is compiled to WebAssembly it produces a WebAssembly module. Every WebAssembly module can import functions from another module, or export a function. All functions are identified by a string. Unlike ‘c’s linking, this string is arbitrary, it can be anything at all, for instance you could have a function identified by the string “I really like fish and chips” complete with spaces. Modules are likewise given string identifiers.
You can denote functions as imported or exported in your code using some ‘c’ intrinsics that the clang compiler provides:
__attribute__((__import_module__(("module name")), __import_name__(("function name"))))
__attribute__((export_name("function name")))
You’d need to place these along side the function you want to import or export. It’s a lot to type and just like Window’s __declspec( dllimport ) and __declspec( dllexport ) it’s a pain which often gets wrapped up in some handy macros, which also help when maintaining a code base which can be compiled both to native code and to WebAssembly:
#ifdef __wasm__
#define WASM_IMPORT(A, B) __attribute__((__import_module__((A)), __import_name__((B))))
#define WASM_EXPORT(A) __attribute__((export_name(A)))
#else
#define WASM_IMPORT(A, B)
#define WASM_EXPORT(A)
#endif
When allows you to use the macros like this:
// example.c
#include <stdint.h>
#ifdef __wasm__
#define WASM_IMPORT(A, B) __attribute__((__import_module__((A)), __import_name__((B))))
#define WASM_EXPORT(A) __attribute__((export_name(A)))
#else
#define WASM_IMPORT(A, B)
#define WASM_EXPORT(A)
#endif
WASM_IMPORT("tracking", "track") void track(int32_t answer);
WASM_EXPORT("add") int32_t add(int32_t a, int32_t b) {
int32_t answer = a + b;
track(answer);
return answer;
}
Which we can compile like this:
$ /opt/wasi-sdk/bin/clang -O2 -Wl,--no-entry -nostdlib -o example.wasm ./example.c
And then we can covert this to the WAT format using the wasm2wat tool - there is a tutorial on setting this up available on an earlier blog post.
$ wasm2wat -o example.wat ./example.wasm
The WAT file (example.wat) shows the export and imported function:
(module
(type (;0;) (func (param i32)))
(type (;1;) (func (param i32 i32) (result i32)))
(import "tracking" "track" (func $track (type 0)))
(func $add (type 1) (param i32 i32) (result i32)
local.get 1
local.get 0
i32.add
local.tee 0
call $track
local.get 0)
(table (;0;) 1 1 funcref)
(memory (;0;) 2)
(global $__stack_pointer (mut i32) (i32.const 66560))
(export "memory" (memory 0))
(export "add" (func $add)))
The exported functions which we can look up by name and execute from the host environment.
In addition to the intrinsics you can specify the functions to export at compile time using command line switches. You may often see this on the web as folks quickly put together a demonstrator:
/opt/wasi-sdk/bin/clang -Wl,--export-all -o output.wasm input.c
Compilation Tips
In summary then, most things will compile over to WebAssembly without significant challenges. But just like any other compilation target there are a few things to watch out for, and a few things to bare in mind, including:
- Everything is an index; Under the hood almost everything in WebAssembly is structured as an index into an array of items. You can see this in the WAT code.
- WebAssembly is a Harvard machine; pointers are indexes into a table.
- WebAssembly is 32 bit; your pointers and
void*will all be 4 bytes not your often expected 8 on 64 bit machines. NULLis a valid memory address; when developing this can be an issue, what would have normally have caused a seg-fault now will work. Remember to do your parameter checking and validation steps, there is no harm in a few extra (assert(ptr != NULL).- Read only data is only really read only at compile time; it can be modified.
- Linking works by exporting and importing functions to / from a WebAssembly module. The compiler has intrinsics which can help you with this, or you can specify functions to export at the command line.